


The EdgeDB team is happy to announce that EdgeDB 1.0 alpha 2 is available for download.
This post highlights some notable changes since the Alpha 1 release and contains benchmarks comparing EdgeDB to different JavaScript database solutions.
What’s EdgeDB
EdgeDB is an advanced open source relational database based on PostgreSQL. The project aims to give developers and data engineers a highly efficient and productive database technology while addressing the shortcomings of SQL and its surrounding ecosystem:
-
high-level data model and type system;
-
a powerful, expressive and extensible query language that allows working with complex data relationships easily;
-
first-class support for schema migrations;
-
support for converting arbitrary strictly typed data to and from JSON via a simple cast operator;
-
out-of-the-box interoperability via REST and GraphQL.
What’s New in Alpha 2
The alpha 2 release includes many new features, bug fixes, and standard library updates. Highlights of this release:
-
Stabilization of the standard library and the EdgeDB binary protocol;
-
Significantly increased test coverage and improvement of DDL and SDL;
-
New dump/restore functionality;
-
A new JavaScript driver implementing the native protocol;
-
Notably improved GraphQL support.
For the full list of changes please read the Alpha 2 Changelog.
New JavaScript Driver
EdgeDB has a new high-performance native EdgeDB driver for NodeJS 10+.
The driver is written in strict TypeScript, thoroughly tested, and has first-class async/await support. It is at least twice as efficient as comparable current PostgreSQL JavaScript drivers.
const edgedb = require("edgedb");
async function main(): void {
const conn = await edgedb.connect(...);
const user = await conn.fetchOne(`
SELECT User {
name,
friends: {
name
}
}
FILTER .id = <uuid>$id
`, {id: ...})
console.log(user);
}
main();Read more about the driver in the docs and see how it performs in the benchmarks below.
Enhanced GraphQL
EdgeDB has advanced built-in GraphQL support. In particular, the ability to use it to query EdgeQL expression aliases means that it is easy to use GraphQL with complex expressions, aggregate functions, and nested filters.
Now, with alpha 2, EdgeDB supports insert, update, and delete mutations as well as filtering by traversing arbitrarily deep links, not just immediate properties:
query {
UserGroup(
filter: {settings: {name: {eq: "notifications"}}}
) {
name
settings {
name
value
}
}
}Dump / Restore
The new dump / restore tooling allows a simple migration path to future EdgeDB versions. This is the time to start evaluating and experimenting with EdgeDB!
Enhanced arbitrary precision types
We have added the new std::bigint scalar type to represent arbitrary integral type. The motivation for the new type is that many platforms lack a true multi-precision decimal type, but implement an arbitrary-precision integer type (JavaScript is a prominent example).
Benchmarks
Here we continue to use the benchmarking arrangement we built for comparing EdgeDB Alpha 1 performance to various Python frameworks and ORMs.
This time we are assessing the code complexity and performance of a simple IMDb-like website built with Loopback, TypeORM, Sequelize, Prisma, Hasura, Postgraphile, raw SQL, and EdgeDB.
The benchmark is designed to require a relatively normalized table layout. The below picture illustrates the benchmark schema:
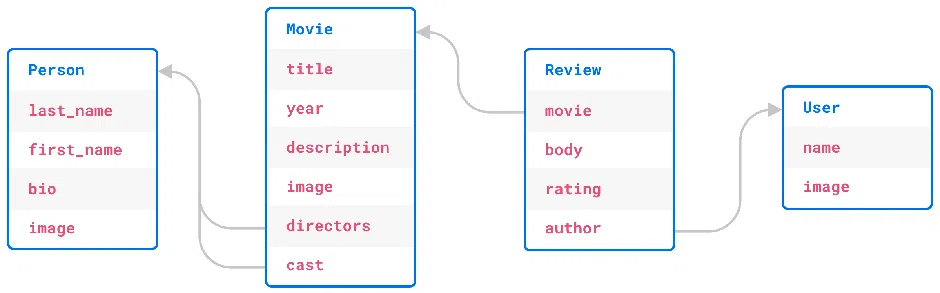
Loopback / TypeORM / Sequelize
Similarly to Python ORMs, each JavaScript ORM has its own API that differs significantly between the libraries. Combined with lack of operator overloading in JavaScript, the ORM client code tends to be very verbose.
Here is a query to fetch a movie, along with some details, cast, and directors expressed with Sequelize:
async movieDetails(id) {
const Movie = this.models.Movie;
const Person = this.models.Person;
const Review = this.models.Review;
const Directors = this.models.Directors;
const Cast = this.models.Cast;
var result = await Movie.findByPk(id, {
include: [
{
model: Person,
as: "directors",
attributes: [
"id",
"first_name",
"middle_name",
"last_name",
"full_name",
"image"
],
through: { attributes: [] }
},
{
model: Person,
as: "cast",
attributes: [
"id",
"first_name",
"middle_name",
"last_name",
"full_name",
"image"
],
through: { attributes: [] }
},
{
separate: true,
model: Review,
as: "reviews",
attributes: ["id", "body", "rating"],
include: ["author"],
order: [["creation_time", "DESC"]]
}
],
order: [
[{ model: Person, as: "directors" }, Directors, "list_order", "ASC"],
[{ model: Person, as: "directors" }, "last_name", "ASC"],
[{ model: Person, as: "cast" }, Cast, "list_order", "ASC"],
[{ model: Person, as: "cast" }, "last_name", "ASC"]
],
benchmark: true
});
result = result.toJSON();
// compute the average rating from the actual fetched reviews
result.avg_rating =
result.reviews.reduce((total, r) => total + r.rating, 0) /
result.reviews.length;
// clean up directors and cast attributes
for (let fname of ["directors", "cast"]) {
result[fname] = result[fname].map(person => {
return {
id: person.id,
full_name: person.full_name,
image: person.image
};
});
}
return JSON.stringify(result);
}The same query expressed with TypeORM:
export async function movieDetails(this, id: number): Promise<string> {
var movie = await this.createQueryBuilder(Movie, "movie")
.select([
"movie.id",
"movie.image",
"movie.title",
"movie.year",
"movie.description",
"directors.list_order",
"cast.list_order",
"dperson.id",
"dperson.first_name",
"dperson.middle_name",
"dperson.last_name",
"dperson.image",
"cperson.id",
"cperson.first_name",
"cperson.middle_name",
"cperson.last_name",
"cperson.image",
"review.id",
"review.body",
"review.rating",
"user.id",
"user.name",
"user.image"
])
.leftJoinAndSelect("movie.directors", "directors")
.leftJoinAndSelect("directors.person", "dperson")
.leftJoinAndSelect("movie.cast", "cast")
.leftJoinAndSelect("cast.person", "cperson")
.leftJoinAndSelect("movie.reviews", "review")
.leftJoinAndSelect("review.author", "user")
.where("movie.id = :id", { id: id })
.orderBy("directors.list_order", "ASC")
.addOrderBy("dperson.last_name", "ASC")
.addOrderBy("cast.list_order", "ASC")
.addOrderBy("cperson.last_name", "ASC")
.addOrderBy("review.creation_time", "DESC")
.getOne();
movie.avg_rating =
movie.reviews.reduce((total, r) => total + r.rating, 0) /
movie.reviews.length;
for (let fname of ["directors", "cast"]) {
movie[fname] = movie[fname].map(rel => {
return {
id: rel.person.id,
full_name: rel.person.get_full_name(),
image: rel.person.image
};
});
}
movie.reviews = movie.reviews.map(rev => {
delete rev.creation_time;
return rev;
});
var result = movie;
return JSON.stringify(result);
}TypeORM basically exposes a query building API that requires the user to know SQL well. Sequelize and Loopback have higher level APIs but still are lacking in features compared to their Python counterparts.
Raw SQL
Using raw SQL is always an option. For this benchmark we are using the most popular PostgreSQL driver for NodeJS: pg.
The code we ended up to fetch movie details via the pg/SQL combination is a bit too long for this post to be included. Please find it here.
EdgeDB
One of the key advantages of using EdgeDB is a common way of fetching object hierarchies: EdgeQL.
The same query can be used to fetch results as JSON or rich objects in Python or JavaScript. Here’s a query to fetch movie details:
SELECT Movie {
id,
image,
title,
year,
description,
avg_rating,
directors: {
id,
full_name,
image,
}
# list_order is a property on the
# "directors" link.
ORDER BY @list_order EMPTY LAST
THEN .last_name,
cast: {
id,
full_name,
image,
}
ORDER BY @list_order EMPTY LAST
THEN .last_name,
reviews := (
# The schema defines a link from Review to Movie,
# so here we are traversing the link in the
# reverse direction.
SELECT Movie.<movie[IS Review] {
id,
body,
rating,
author: {
id,
name,
image,
}
}
ORDER BY .creation_time DESC
),
}
FILTER .id = <uuid>$idYou can use it to fetch data as JSON with:
await connection.fetchOneJSON(movieQuery, { id: id });or as JavaScript objects:
await connection.fetchOne(movieQuery, { id: id });and here’s comparable Python code:
await connection.fetchone_json(movie_query, id=id)
# or
await connection.fetchone(movie_query, id=id)Results
The JavaScript benchmarks were run on a similar server configuration and on the same dataset as Python benchmarks in our alpha 1 blog post:
-
Databases were run on a separate 12-core GCP instance. The instance was configured to have 16GB RAM and an SSD.
-
Benchmarks were run on a separate 8-core GCP instance with 12GB RAM and an SSD.
-
The concurrency level was set to 24, and each JavaScript client was running in async mode, i.e. in a single process with 24 non-blocking connections to the server.
-
Every benchmark was tested by running it in a tight loop for 30 seconds, with 10 seconds of warmup.
The full report is available here.
A few comments on the benchmark results:
-
JavaScript ORMs—Loopback, TypeORM, and Sequelize—typically exhibit very poor performance. In one case TypeORM is 50x slower than using raw SQL and 200x slower than querying EdgeDB. The primary reason is twofold: inefficient queries generated by the ORM plus expensive client-side aggregation of results.
-
Due to the limitations of the pg library we are unable to effectively express all cases as a single SQL query so we have to issue several smaller SQL queries, which impacts latency due to multiple server roundtrips. The overhead of the
pgdriver also seems to be higher than that of edgedb-js in general. -
EdgeDB performs well in this benchmark. The JSON variant of the benchmark performs better because it does not create rich data objects and avoids spending any additional CPU manually serializing data to JSON. EdgeDB also requires less code to setup the database schema and fetch data than any JavaScript ORM library.
Next: Alpha 3
In the time since the last release we have grown our engineering team and are accelerating our efforts to bring EdgeDB to production-ready 1.0.
Moving forward we are switching to a faster release cadence. Alpha 3 is going to be about improving EdgeDB schema migrations support.
In the meantime we encourage you give EdgeDB a try and join our community chat!
